-
![宝塔初始化mysql]()
MYSQL
2024-12-22 18:05:57
1079°
0
刚安装的mysql无法远程链接,怎么处理?
-
![nginx禁用ip访问]()
LINUX
2023-03-28 10:48:37
1979°
0
nginx禁用ip访问
-
![linux查看文件夹大小、磁盘使用情况及内存占用情况]()
LINUX
2022-10-09 10:09:50
2884°
0
linux查看文件夹大小、磁盘使用情况及内存占用情况
-
![SVN常用命令汇总]()
杂谈
2022-09-26 11:05:59
2568°
0
SVN常用命令汇总
-
![解决pcntl_fork() has been disabled for security reasons in file...错误]()
PHP
2021-12-13 10:39:57
3094°
0
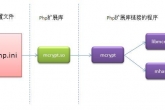
wokerman启动的时候遇到了一个问题,无法启动。打开php.ini文件,找到disable_functions这个里面的以pcntl开头开头的函数都去掉,然后保存,重新启动一下php就好了。
-
![thinkphp6跨域请求报Access-Control-Allow-Origin、Access-Control-Allow-Headers错误的解决方法]()
PHP
2021-12-08 14:21:23
4739°
0
这是常见的跨域请求问题,在前后端分离的项目中常见,前端项目直接用接口域名请求,根据浏览器的网络请求规则,跨域是不允许这样直接调用的(会被当黑客恶意攻击给拦截掉),从而导致该跨域请求被拒绝。
-
![亚马孙s3上传文件报Error executing]()
PHP
2021-11-29 10:29:27
2751°
0
亚马孙上传文件报错:Error executing "PutObject" on "https://animehubonline-bucket.s3.us-west-2.amazonaws.com/2a7c7491a8a0c57d064657120ffafd90.png"; AWS HTTP error: cURL error 60: (see https://curl.haxx.se/libcurl/c/libcurl-errors.html)
-
![php使用redis的锁机制解决缓存雪崩及商城订单超卖的问题]()
PHP
2021-11-26 11:20:24
2671°
0
php使用redis加锁的同时给锁设置过期时间,利用锁机制解决缓存雪崩及商城订单超卖。
-
![PHP使用yield处理大文件读取及数据库大数据量读取]()
PHP
2021-11-11 17:26:30
2829°
0
yield和return有点像,它是一个生成器, 只有在你调用他的时候才会执行,并不产生多余的值。比如读取一个很大的文件,如果直接读取很有可能内存就爆了,而yield就可以做到把数据一行行读取到php运行内存,并非一次性读取到php运行内存。
-
![beyond compare 过期的解决方法]()
杂谈
2021-11-11 11:13:43
2846°
0
beyond compare是一个很好用的文件对比工具,如果过期了可以通过本文介绍的方法来继续使用。
-
![如何修改mysql的默认时区?]()
MYSQL
2021-10-20 14:53:42
2409°
0
MySQL 时区默认是服务器的时区,可以通过命令进行修改,也可以修改mysql的配置文件。
-
![MySQL报You can't specify target table for update in FROM clause]()
MYSQL
2021-10-18 16:53:46
2628°
0
MySQL报You can't specify target table for update in FROM clause错误的意思是说,不能先select出同一表中的某些值,再update这个表。
-
![centos重启系统后服务器时间总是被还原的解决方案]()
LINUX
2021-10-11 11:44:11
4300°
0
centos重启系统后,发现调用其他平台接口时会报各种错误,经过排查是服务器时间不一致造成的;然后手动修改了系统时间,结果之后重启服务器,又发现时间不一致。
-
![gitlab自动同步代码到web站点]()
杂谈
2021-08-10 13:32:26
3047°
0
安装gitlab后如何将git仓库中的代码自动实时同步到网站目录下?
-
![在docker环境下安装php的常用扩展]()
安装教程
2021-05-11 10:35:17
2707°
0
在docker环境下安装php的常用扩展gd、memcached、redis、bcmath、pdo_mysql
-
![在docker容器中安装php扩展的方法]()
安装教程
2021-05-10 16:38:24
2843°
0
在docker容器中添加php的各种扩展
-
![docker安装php+nginx+mysql搭建开发环境]()
安装教程
2021-05-08 17:38:14
2629°
0
使用docker快速搭建php开发环境。
-
![docker入门教程]()
安装教程
2021-05-06 16:15:17
2810°
0
Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从 Apache2.0 协议开源。Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口(类似 iPhone 的 app),更重要的是容器性能开销极低。
-
![PHP接口访问频率限制]()
PHP
2021-03-03 11:13:39
3606°
0
如果要限制某个接口一分钟之内只能访问10次。有很多人都会想当然的通过redis设置一个过期时间为1分钟的key,那么这样会存在一个问题。在59秒的时候接口访问了10次,然后key马上就过期了,下一秒访问的时候又可以访问10次,这样根本就没有达到1分钟之内访问10次的需求。
-
![php中三个点...的用法]()
PHP
2021-03-03 10:36:36
2979°
0
PHP 在用户自定义函数中支持可变数量的参数列表。由 ... 语法实现。